先用一分钟看懂:这篇论文到底在干嘛?
它研究的是:表格任务里,怎样让 LLM 更靠谱地帮我们做特征工程。核心不是让 LLM 自己全权决定,而是把工作拆开。
LLM 很会“想特征”,但不一定会“判断哪个特征真有用”。所以本文让 LLM 负责生成候选特征,再用一个会估计收益和不确定性的模型来挑选,必要时才问人类专家二选一。
原来的做法
LLM 既生成特征,也自己决定用哪个。问题是它的判断可能只是“听起来合理”,不一定真的能提高模型效果。
本文的做法
LLM 只负责提出一批候选。系统用 BNN 预测每个候选可能带来的收益,再用 UCB 选择最值得试的那个。
人类怎么参与
人类不用写特征,也不用每轮审核。只有当系统拿不准两个候选哪个更好时,才让人类做一次简单的二选一。
背景:表格学习里的老问题,被 LLM 重新点燃。
表格数据仍然是风控、推荐、医疗、用户转化等场景的主力数据形态。模型性能很大程度上取决于特征工程: 原始列 \(x_i \in \mathbb{R}^d\) 是否能被转换为更贴近任务机制的新表示。
传统 AutoML
OpenFE、AutoGluon 等方法通常在预定义算子空间里搜索组合。优点是工程稳定,缺点是缺乏任务语义,容易制造重复或低价值特征。
它像一个勤快的“公式试验机”,会机械地试加减乘除、分箱、交叉等组合,但不太懂列名背后的业务含义。
LLM 特征工程
CAAFE、OCTree 等工作利用任务描述、列名和历史反馈,让 LLM 生成新特征。它们能利用语义知识,但经常让 LLM 同时负责“提出”和“选择”。
LLM 更像有业务常识的助手,能想到“数字体验”“健康风险组合”这类有意义的特征,但它不一定知道这些特征是否真能涨分。
本文切入点
作者质疑:LLM 的内部启发式并没有校准的效用和不确定性估计。有限迭代预算下,黑箱选择会浪费评估机会。
所以本文关注的不是“怎么让 LLM 多生成”,而是“生成之后怎么更聪明地选”。
解决什么问题:不是缺少候选,而是缺少可信的选择机制。
当前 LLM-powered feature engineering 的隐含假设是:LLM 既会想特征,也会知道哪些特征值得评估。本文认为这个假设太强。
黑箱优化的三个症状
无校准效用无不确定性重复低收益探索
LLM 可能反复提出看起来合理但边际收益很低的 transformation;当迭代预算 \(T\) 很小,错误选择的代价很高。
人类专家的价值
人类未必能直接给每个特征打分,但擅长 pairwise preference:在两个候选操作 \(e_a,e_b\) 之间判断哪个更有希望。
关键是不能每轮都问人,否则认知成本爆炸;必须“值得问时才问”。
例如:预测贷款批准时,让专家在“贷款额/收入”和“年龄平方”之间选一个,通常比让专家估计“能提升多少 AUROC”容易得多。
目前的方法:AutoML 靠算子搜索,LLM 方法靠语义启发式。
本文的位置很清晰:它不是替换 LLM,也不是替换 AutoML,而是把 LLM 生成能力接到一个更有原则的选择层上。
非 LLM baseline
OpenFE:自动构造并筛选特征,依赖预定义 transformation operators。
AutoGluon:端到端 AutoML 系统,包含自动预处理、模型选择与集成能力,但不是专门利用任务语义生成新特征。
LLM baseline
CAAFE:用任务描述和列语义 prompt LLM,迭代生成 semantically meaningful features。
OCTree:把 LLM 作为黑箱优化器,结合验证分数和决策树蒸馏出的 verbalized reasoning 来提出与改进 feature generation rules。
本文方法:LLM 只提案,BNN+UCB 做选择,人类只在高价值不确定时介入。
整体流程可以顺着“候选生成 → 表示编码 → 代理建模 → UCB 选择 → 选择性偏好反馈 → 评估并更新数据集”理解。
可以把系统想成一个招聘流程:LLM 像猎头,负责推荐很多候选人;BNN 像评估官,预测每个人可能表现如何以及评估有多不确定;UCB 像面试策略,既看当前评分,也给潜力股机会;人类专家只在两个候选很难分出高下时参与面试。
创新点 1:解耦 proposal 与 selection
LLM 的强项是语义联想和候选生成;选择则交给显式的 utility/uncertainty model。这是本文最重要的工程和建模判断。
创新点 2:把人类反馈变成“预算化观测”
人类反馈不是无条件加入,而是有两个触发条件:候选置信区间必须重叠,且潜在收益上界必须超过反馈成本 \(\gamma_\kappa\)。
数学表示与建模:从 feature operation 到带偏好反馈的 Bayesian selection。
1. 任务与效用函数
数据集 \(D=\{(x_i,y_i)\}_{i=1}^{n}\),其中 \(x_i \in \mathbb{R}^d\),列集合 \(C=\{c_1,\ldots,c_d\}\)。每个 feature transformation operation \(e \in \mathcal{E}\) 将原数据矩阵 \(X\in\mathbb{R}^{n\times d}\) 映射为新列 \(z_e\in\mathbb{R}^n\)。
把候选特征 \(e\) 加进数据表,重新训练一次模型,再看验证集分数。这个分数就是该特征的真实价值 \(g(e)\)。问题是,每测一次都要训练模型,所以很贵。
每轮目标是 \(e_t^\star=\arg\max_{e\in\mathcal{E}}g(e)\)。但 \(g(e)\) 只有在训练下游模型并验证后才能观测,因此是昂贵黑箱。
2. LLM 候选生成
第 \(t\) 轮时,LLM 会根据历史上试过哪些特征、效果如何、当前数据列是什么、任务目标是什么,生成一批候选特征 \(S_t\)。
区别于 CAAFE/OCTree,本文不让 \(M\) 直接选择最终 \(e_t\),而是只把 \(M\) 当作 proposal distribution。
3. 操作表示 \(\phi(e)\)
系统要先把“一个特征操作”变成模型能读的向量。这个向量由两部分组成:一部分表示这段操作的语义,另一部分明确标记它用了哪些原始列。
\(\phi_{\mathrm{embedding}}\) 使用 OpenAI text-embedding-3-small;\(\phi_{\mathrm{column}}\) 显式告诉代理模型这个候选特征用到了哪些原始列,弥补自然语言 embedding 对相似列名的混淆。
4. BNN surrogate 与变分后验
作者选择 Bayesian Neural Network 而非 Gaussian Process,因为候选操作是高维语言派生表示,且非平稳性强。后验 \(P(\theta\mid H_t)\) 不可直接求,使用 \(q_t(\theta)=\mathcal{N}(\theta;M_t,\Sigma_t)\) 做变分近似:
实验中先验设为 \(P(\theta)=\mathcal{N}(0,I)\)。预测均值与不确定性为:
BNN 对每个候选特征输出两个数:\(\mu_t(e)\) 是“我预测它有多好”,\(\sigma_t(e)\) 是“我对这个预测有多没把握”。本文后面的选择策略就靠这两个数。
5. UCB 选择
在置信事件下,\(|g(e)-\mu_t(e)|\le \sqrt{\beta_t}\sigma_t(e)\)。其中 \(\delta=0.1\),\(\beta_t=2\log\left(\frac{|S_t|\pi^2t^2}{3\delta}\right)\)。
UCB 分数 = 预测收益 + 不确定性奖励。一个特征如果预测收益高,会被选;如果预测收益一般但模型很不确定,也可能因为“潜在惊喜”被选。LCB 则是比较保守的下界估计。
无人在环时,直接选择 \(e_t^a=\arg\max_{e\in S_t}\mathrm{UCB}_t(e)\)。
6. 选择性人类偏好反馈
人类专家是随机 oracle \(\kappa\),对候选对 \((e_t^a,e_t^b)\) 给出 \(Z_t\in\{+1,-1\}\)。论文先选 \(e_t^a\) 为 UCB 最优,再选 \(e_t^b=\arg\max_{e\in S_t\setminus\{e_t^a\}}\mathrm{UCB}_t(e)\)。
问人类有没有价值,取决于人类反馈是否可能让系统从当前选择 \(e_t^a\) 切换到更好的 \(e_t^b\)。如果 \(e_t^b\) 的最好情况都比不过 \(e_t^a\) 的保守情况,那就没必要问人。
触发人类查询必须同时满足:
第一,两个候选的可能表现范围要有重叠,说明确实难分胜负;第二,不确定性要足够大,说明问人类可能带来足够收益,值得付出认知成本。
实验中 \(\gamma_\kappa=4\),偏好置信度超参数 \(\eta=1\)。偏好似然采用 probit:
偏好反馈被视为关于两个候选相对效用的概率观测,而不是硬规则。这一点很关键:人类可能错,模型也可能错,posterior fusion 才是协作。
实验方法与设计:主实验、可扩展性、真实用户研究三条线。
主实验设置
数据:18 个表格数据集,其中 13 个分类、5 个回归;每个数据集随机 80%/20% 划分 train/validation,结果平均 5 次运行。
LLM:GPT-4o 主实验,temperature \(=1\),每轮生成 15 个候选,最大迭代 \(T=50\)。额外比较 DeepSeek-V3、GPT-3.5-Turbo、GPT-4o、GPT-5。
下游模型:MLP 与 XGBoost。分类指标为 AUROC,回归指标为 normalized RMSE。
怎么看:作者不是只在一个模型上试,而是用 MLP 和 XGBoost 两种不同下游模型,检查生成的特征是否普遍有帮助。
Baseline
OpenFEAutoGluonCAAFEOCTree
OpenFE/AutoGluon 代表非 LLM AutoML 特征工程;CAAFE/OCTree 代表 LLM-based feature engineering。非 LLM 方法跑到收敛,LLM 方法统一迭代预算。
怎么看:如果本文方法超过 CAAFE/OCTree,说明收益不只是来自“用了 LLM”,而是来自“更会选择 LLM 候选”。
算法 1:Iterative Selection of LLM-Proposed Feature Transformation Operations
Input: D_train, D_eval, LLM M, tabular learner f, budget T
Initialize H_1 = empty, feature operation pool S_0 = empty
for t = 1 ... T:
S_t = {operations proposed by M in round t} union S_{t-1} minus {previously selected}
Fit surrogate q_t(theta) using history H_t
e_a = argmax_e UCB_t(e)
if human expertise is unavailable:
e_selected = e_a
else:
e_b = argmax_{e in S_t \ {e_a}} UCB_t(e)
if overlap and uncertainty trigger conditions hold:
Z_t = kappa(e_a, e_b)
update posterior q'_t(theta) using preference likelihood
e_selected = argmax_{e in {e_a,e_b}} UCB_t(e)
else:
e_selected = e_a
Fit f on D_train plus e_selected; evaluate g(e_selected) on D_val plus e_selected
H_{t+1} = H_t union {(e_selected, g(e_selected))}
if g(e_selected) > 0:
append the new feature column to D_train and D_val
return selected operations and updated datasetsLLM 生成候选的 prompt 模板
You are an expert data scientist with deep expertise in feature engineering.
Dataset Context:
- Task type: [CLASSIFICATION_OR_REGRESSION]
- Metric: [ROC_AUC_OR_OTHER]
- Columns (name:type): [COLS_WITH_TYPES]
- Target: <TARGET_NAME>
- Notes (missingness, skew, constraints): <DATA_NOTES>
Recent performance feedback: [PERFORMANCE HISTORY]
Remaining iteration budget: [BUDGET]
Suggest up to K complementary NEW features as a JSON list.
Each item includes:
{
"name": "snake_case_identifier",
"explanation": "why this feature helps",
"reasoning": "what history pattern informs this choice",
"code": "feature = <python expression using df[...] + helper ops>",
"expected_benefit": "specific hypothesis"
}
Rules: no label leakage; avoid rejected patterns; build on successful features;
combine multiple columns when useful; keep candidates diverse; return JSON only.模拟人类专家偏好的 prompt 模板
You are a senior ML scientist specializing in tabular feature engineering.
Use dataset context and SHAP-based feature importances to judge which of
two candidate feature operations is more likely to improve the downstream metric.
Prefer: high-SHAP columns, useful transformations, interactions, ratios,
bins, complementary and robust features.
Penalize: duplicated, noisy, fragile, or label-leaking features.
Output JSON only:
{ "choice": "A" | "B" }数据集清单
| Dataset | 描述 | #Features | #Instances | Task |
|---|---|---|---|---|
| flight | 基于航班计划与航空属性预测延误/满意度相关分类任务 | 22 | 25,976 | Classification |
| wine | 基于理化测试结果分类葡萄酒质量 | 11 | 945 | Classification |
| loan | 基于人口统计和财务属性预测贷款批准 | 13 | 45,000 | Classification |
| diabetes | 基于女性患者医疗测量诊断糖尿病 | 21 | 40,000 | Classification |
| titanic | 基于人口统计和票务信息预测 Titanic 生还 | 8 | 891 | Classification |
| travel | 预测客户是否购买旅游保险或提出 claim | 8 | 63,326 | Classification |
| ai usage | 预测受访者是否报告使用 AI 工具 | 8 | 10,000 | Classification |
| water | 基于理化指标判断水是否可饮用 | 9 | 3,276 | Classification |
| heart | 基于临床测量诊断心脏病 | 11 | 918 | Classification |
| adult | 基于人口普查属性预测收入是否超过 $50K | 14 | 32,561 | Classification |
| customer | 基于电信使用统计预测客户流失 | 20 | 7,043 | Classification |
| personality | 基于问卷回答预测 Big Five 人格类型 | 7 | 2,900 | Classification |
| conversion | 预测在线购物者是否转化购买,私有公司数据 | 178 | 15,000 | Classification |
| housing | 基于房屋信息预测房价 | 9 | 20,640 | Regression |
| forest | 基于地理信息预测森林火灾 burned area | 12 | 517 | Regression |
| bike | 基于天气与日历信息预测每日自行车租赁数 | 9 | 17,414 | Regression |
| crab | 基于生物测量预测螃蟹年龄 | 8 | 3,893 | Regression |
| insurance | 预测保险费用 | 6 | 1,339 | Regression |
实验结果:主要收益来自“会选”,人类反馈进一步推高上限。
先看结论:Ours w/o human 已经普遍超过 baseline,说明 BNN+UCB 的选择机制本身有效;Ours w/ human 通常更高,说明在关键不确定时加入人类偏好还能继续提升。
分类主结果:Table 1,AUROC (%)
下表保留论文 Table 1 的具体数值。蓝色为该行最佳本文方法;绿色为最佳 baseline。括号为相对最佳 baseline 的 error reduction。
表格怎么看:AUROC 越高越好。你可以横着看每个数据集:如果 Ours w/o 或 Ours w/ 比 OpenFE、AutoGluon、CAAFE、OCTree 更高,就说明本文方法造出的特征让模型区分正负样本的能力更强。
| Dataset | MLP OpenFE | MLP AutoGluon | MLP CAAFE | MLP OCTree | MLP Ours w/o | MLP Ours w/ | XGB OpenFE | XGB AutoGluon | XGB CAAFE | XGB OCTree | XGB Ours w/o | XGB Ours w/ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| flight | 93.3 | 92.6 | 92.9 | 94.8 | 96.9 (+40.4%) | 97.3 (+48.1%) | 95.7 | 95.4 | 95.2 | 96.4 | 97.6 (+33.3%) | 98.0 (+44.4%) |
| wine | 77.2 | 77.2 | 77.6 | 78.2 | 78.5 (+1.4%) | 78.7 (+2.3%) | 81.3 | 81.0 | 80.9 | 82.1 | 82.9 (+4.5%) | 83.3 (+6.7%) |
| loan | 95.3 | 95.4 | 95.7 | 95.9 | 96.0 (+2.4%) | 96.1 (+4.9%) | 96.2 | 96.0 | 96.1 | 96.5 | 96.9 (+11.4%) | 97.1 (+17.1%) |
| diabetes | 81.1 | 82.4 | 82.8 | 82.8 | 83.0 (+1.2%) | 83.0 (+1.2%) | 84.1 | 83.9 | 83.9 | 84.4 | 85.2 (+5.1%) | 84.8 (+2.6%) |
| titanic | 84.1 | 84.3 | 86.3 | 86.5 | 86.8 (+2.2%) | 87.0 (+3.7%) | 85.0 | 84.8 | 87.0 | 87.4 | 87.9 (+4.0%) | 88.3 (+7.1%) |
| travel | 80.4 | 80.3 | 81.1 | 81.7 | 82.0 (+1.6%) | 82.3 (+3.3%) | 83.6 | 83.2 | 83.6 | 84.6 | 85.3 (+4.5%) | 85.7 (+7.1%) |
| aiusage | 67.8 | 67.5 | 68.2 | 68.0 | 68.5 (+0.9%) | 68.3 (+0.3%) | 71.8 | 71.5 | 71.3 | 72.4 | 73.3 (+3.3%) | 73.8 (+5.1%) |
| water | 53.7 | 53.2 | 56.7 | 57.9 | 58.7 (+1.9%) | 59.3 (+3.3%) | 56.7 | 56.1 | 59.8 | 61.7 | 63.2 (+3.9%) | 64.1 (+6.3%) |
| heart | 92.2 | 92.3 | 92.6 | 93.1 | 93.4 (+4.3%) | 93.6 (+7.2%) | 93.6 | 93.5 | 93.6 | 94.3 | 95.1 (+14.0%) | 94.8 (+8.8%) |
| adult | 90.5 | 90.4 | 90.8 | 90.9 | 91.3 (+4.4%) | 91.4 (+5.5%) | 91.6 | 91.3 | 91.5 | 92.0 | 92.4 (+5.0%) | 92.8 (+10.0%) |
| customer | 84.6 | 84.5 | 84.9 | 84.8 | 85.1 (+1.3%) | 85.1 (+1.3%) | 85.3 | 85.0 | 85.3 | 85.2 | 85.8 (+3.4%) | 86.3 (+6.8%) |
| personality | 94.4 | 94.1 | 95.0 | 95.4 | 96.1 (+15.2%) | 96.1 (+15.2%) | 96.4 | 96.2 | 96.6 | 97.1 | 97.4 (+10.3%) | 97.6 (+17.2%) |
| conversion | 90.7 | 90.6 | 90.9 | 91.1 | 92.6 (+16.9%) | 92.9 (+20.2%) | 91.2 | 91.9 | 92.1 | 92.4 | 93.5 (+5.7%) | 93.9 (+11.5%) |
平均分类收益
MLP 下,Ours w/o human 对最佳 baseline 的平均 error reduction 为 7.24%,w/ human 为 8.96%。
XGBoost 更明显
XGBoost 下,Ours w/o human 为 9.02%,w/ human 为 11.23%。
私有数据验证
conversion 数据集不可被 LLM 训练语料直接记忆。MLP 下 OCTree 91.1,Ours w/ human 92.9。
不同 LLM backbone:Table 2,平均 AUROC (%)
| Backbone | MLP OpenFE | MLP AutoGluon | MLP CAAFE | MLP OCTree | MLP Ours w/o | MLP Ours w/ | XGB OpenFE | XGB AutoGluon | XGB CAAFE | XGB OCTree | XGB Ours w/o | XGB Ours w/ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DeepSeek-V3 | 83.5 | 83.5 | 84.9 | 85.5 | 86.1 | 86.4 | 85.6 | 85.4 | 86.6 | 87.3 | 88.2 | 88.6 |
| GPT-3.5-Turbo | 83.5 | 83.5 | 83.2 | 84.2 | 84.6 | 85.1 | 85.6 | 85.4 | 85.2 | 86.0 | 86.5 | 87.1 |
| GPT-4o | 83.5 | 83.5 | 84.3 | 84.7 | 85.3 | 85.5 | 85.6 | 85.4 | 85.9 | 86.7 | 87.4 | 87.4 |
| GPT-5 | 83.5 | 83.5 | 85.5 | 85.8 | 85.9 | 86.5 | 85.6 | 85.4 | 87.1 | 87.7 | 88.0 | 88.7 |
迭代轨迹与用户研究
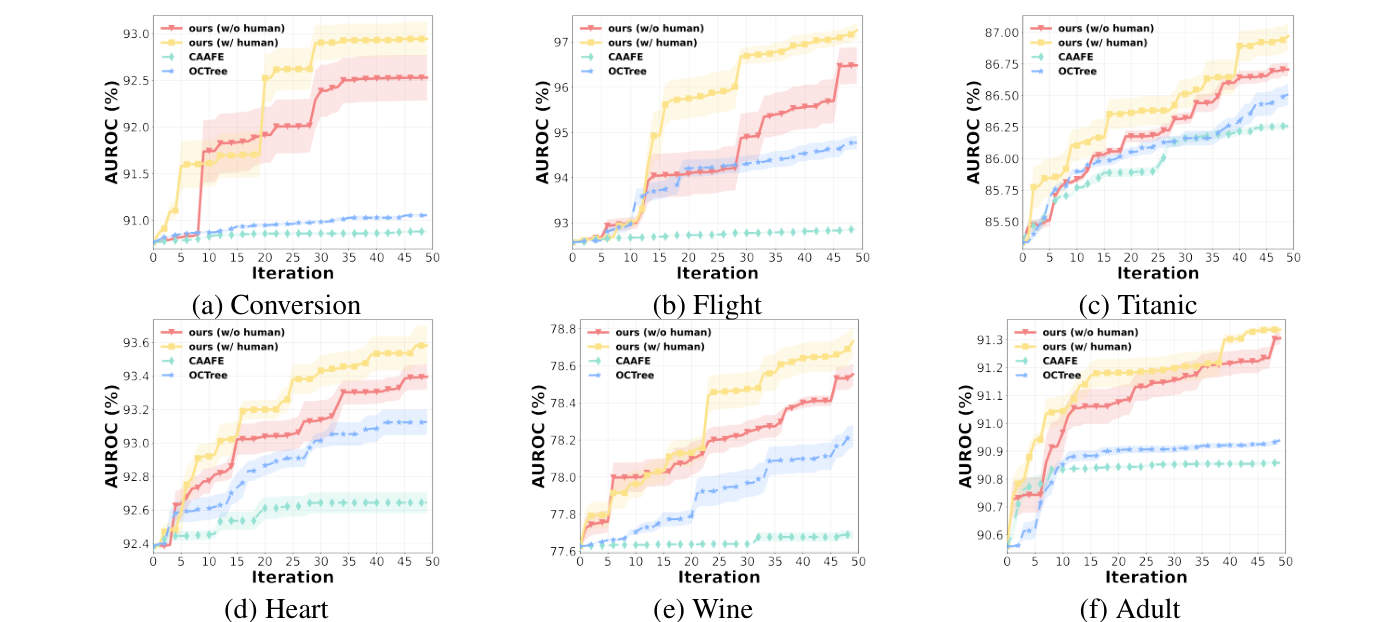
Figure 1:每条线表示一种方法随迭代轮数增加的 AUROC。黄色/红色是本文方法,整体比 CAAFE/OCTree 更快上升、更少停滞,说明它更会把有限迭代花在有价值的特征上。
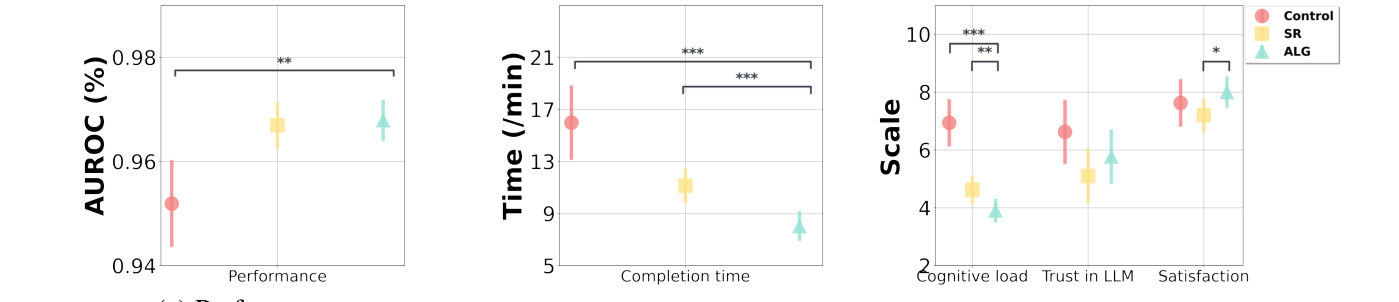
Figure 2:真实用户研究。左图看最终 AUROC,ALG 更高;中图看完成时间,ALG 更短;右图看用户体验,ALG 的认知负荷更低、满意度更高。意思是本文方法不仅效果好,也让人更省力。
可扩展性:Table 3/4
| Features | LLM(s) | Surrogate(s) | UCB(s) | Eval(s) |
|---|---|---|---|---|
| 10 | 1.82 | 0.17 | 0.006 | 1.79 |
| 50 | 1.82 | 0.16 | 0.005 | 1.24 |
| 100 | 1.82 | 0.19 | 0.005 | 1.78 |
| 1,000 | 1.82 | 0.20 | 0.009 | 8.40 |
| 10,000 | 1.82 | 0.57 | 0.018 | 23.40 |
| Samples | LLM(s) | Surrogate(s) | UCB(s) | Eval(s) |
|---|---|---|---|---|
| 1,000 | 1.82 | 0.17 | 0.005 | 0.28 |
| 5,000 | 1.82 | 0.18 | 0.005 | 0.89 |
| 10,000 | 1.82 | 0.23 | 0.006 | 1.47 |
| 50,000 | 1.82 | 0.18 | 0.006 | 5.22 |
| 100,000 | 1.82 | 0.18 | 0.005 | 10.65 |
作者结论:BNN surrogate 与 UCB 计算主要在 feature-operation 层面工作,对样本数几乎不敏感;瓶颈仍是 LLM 调用和下游模型评估。
回归任务补充:Table C.2,normalized RMSE,越低越好
| Dataset | MLP OpenFE | MLP AutoGluon | MLP CAAFE | MLP OCTree | MLP Ours w/o | MLP Ours w/ | XGB OpenFE | XGB AutoGluon | XGB CAAFE | XGB OCTree | XGB Ours w/o | XGB Ours w/ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| housing | 0.316 | 0.319 | 0.292 | 0.283 | 0.270 | 0.266 | 0.228 | 0.231 | 0.224 | 0.221 | 0.216 | 0.214 |
| forest | 1.851 | 1.851 | 1.750 | 1.724 | 1.655 | 1.621 | 1.448 | 1.469 | 1.421 | 1.418 | 1.402 | 1.398 |
| bike | 0.295 | 0.302 | 0.282 | 0.274 | 0.262 | 0.261 | 0.216 | 0.219 | 0.211 | 0.208 | 0.203 | 0.201 |
| crab | 0.286 | 0.288 | 0.258 | 0.252 | 0.242 | 0.239 | 0.226 | 0.230 | 0.224 | 0.222 | 0.219 | 0.217 |
| insurance | 0.511 | 0.512 | 0.473 | 0.462 | 0.467 | 0.462 | 0.384 | 0.385 | 0.382 | 0.381 | 0.379 | 0.378 |
复现路线:照这个 checklist 基本能搭出论文系统。
实现组件
1. 数据读取与 80/20 随机划分;2. 下游 MLP/XGBoost 训练评估;3. LLM JSON 候选生成器;4. 特征代码安全执行器;5. operation embedding;6. column usage encoder;7. BNN surrogate;8. UCB selector;9. preference oracle;10. 历史 \(H_t\) 与 accepted feature 管理。
关键超参数
\(T=50\),每轮候选 \(K=15\),temperature \(=1\),\(\delta=0.1\),\(\gamma_\kappa=4\),\(\eta=1\),embedding model 为 text-embedding-3-small,BNN prior 为 \(P(\theta)=\mathcal{N}(0,I)\)。
论文给出的候选特征示例
digital_experience_tensor:
gmean = (df['Inflight wifi service'] * df['Ease of Online booking'] * df['Online boarding']) ** (1/3)
comfort = np.tanh((df['Seat comfort'] + df['Leg room service']) / 2.0)
feature = (gmean * (df['Cleanliness'] ** 0.5)) * comfort
age_weighted_health_interaction:
feature = (df['Age'] * (df['HighBP'] + df['HighChol'] + df['HeartDiseaseorAttack'])) \
/ (1 + df['Smoker'] * df['BMI'])
lifestyle_risk_balance_enhanced:
feature = (df['Fruits'] + df['Veggies'] + df['PhysActivity']) / \
(df['Smoker'] + df['HvyAlcoholConsump'] + df['NoDocbcCost'] + 1)我的评论:想法漂亮,但证据链还有几处会被认真追问。
优势
第一,问题定义非常到位:LLM 最大价值是 proposal,不是 calibrated optimizer。把选择权交给显式 surrogate,是很符合系统设计直觉的。
第二,选择性人类反馈不是装饰,而是嵌进 regret/uncertainty 框架里,有明确触发条件,避免“人在环”沦为口号。
第三,真实用户研究补上了只用 GPT-4o 模拟专家的缺口,显示 ALG 不只提高 AUROC,还降低时间和认知负荷。
不足
最尖锐的问题:主实验的 w/ human 用 GPT-4o+SHAP prompt 模拟人类专家,严格说这不是 human expertise,而是另一个 LLM oracle。它证明了 preference signal 有用,但没有完全证明真实专家在多数据集上同样有用。
第二,\(g(e)>0\) 才接受新特征的规则依赖“utility 是否相对基线定义为增益”。论文公式写的是验证得分 \(J\),这里存在表述不够严谨的问题。
第三,BNN 的结构、训练细节、优化轮数、MC 采样数没有在抽取到的正文中充分展开;若要完全复现,仍需作者代码或更详细 appendix。
可能改进
可以加入 ablation:只用 embedding、不用 column encoder;GP/随机森林/深度 ensemble 作为 surrogate;不同 \(\gamma_\kappa\) 下的人类查询次数与收益曲线。
还应报告 feature execution failure rate、重复特征率、候选合法性,以及每轮实际触发人类反馈的比例。否则很难判断 gains 来自 selection、filtering 还是代码执行策略。
我会怎么打分
作为 ICLR 论文,我会倾向 weak accept 到 accept:核心 framing 很强,实验覆盖面不错,用户研究加分;但模拟人类反馈和复现细节不足会压低置信度。
这篇论文真正有意思的地方,是它把“LLM agent”重新拆回了可控系统。
它没有继续堆更强 prompt 或更强模型,而是问:LLM 哪部分能力可靠,哪部分不可靠? 答案是:生成候选可靠一些,评估与选择不可靠。于是系统把 LLM 放在高召回的生成位置,把选择交给 uncertainty-aware optimization,把人类放在低频但高杠杆的 pairwise 判断位置。 这比“让 LLM 端到端自治”更像一个能进生产环境的研究方向。