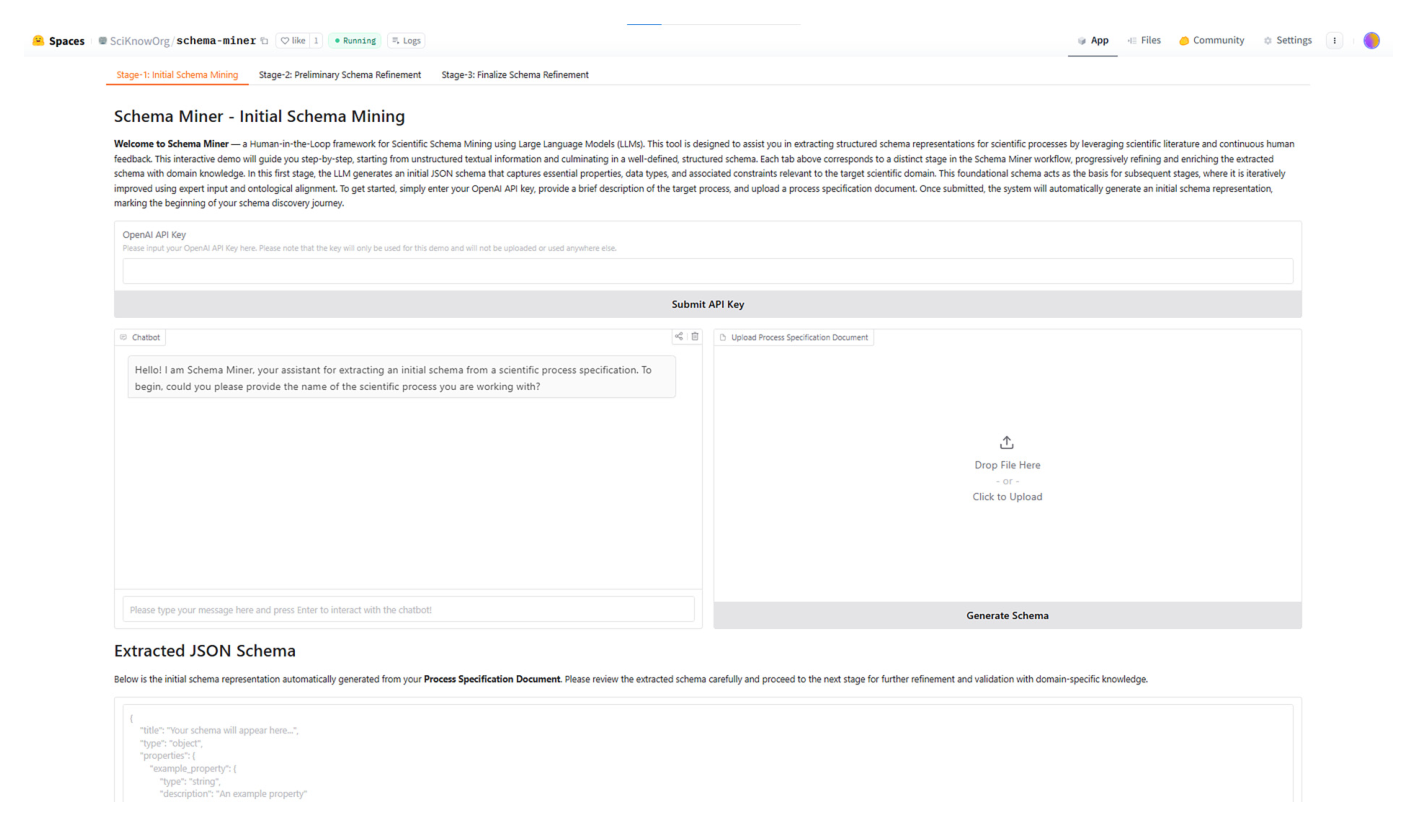
SCHEMA-MINERpro: 让机器读懂科学实验流程
这篇论文想让机器真正读懂科学实验流程。
论文里的实验步骤原本是一段段自然语言。SCHEMA-MINERpro 做的事,是把它们整理成标准化 schema,再把温度、压力、时间、能量这些字段连到 QUDT 本体,让它们可以被搜索、比较和复用。
一句话
它把“论文里写的实验描述”变成“机器能懂的实验卡片”。
LLM 读论文专家纠错Agent 对齐本体QUDT 统一单位最核心的价值
以后你可以问机器:“找出所有低于 (200^\circ C)、使用 TMA precursor 的 ALD 实验”,而不是人工一篇篇翻论文。
先看一个例子
假设一篇 ALD 论文里有一句话:
论文原文
The Al₂O₃ film was deposited at 200 °C using trimethylaluminum and H₂O. The TMA pulse time was 0.1 s, followed by a 5 s N₂ purge. The growth per cycle was 1.1 Å/cycle.
机器真正需要的结构
process: Atomic Layer Deposition material: Al2O3 precursors: TMA, H2O temperature: 200 °C pulse_time: 0.1 s purge_time: 5 s growth_per_cycle: 1.1 Å/cycle
第一步只是把句子拆成字段。但这还不够,因为机器还不知道 temperature 是标准温度概念,也不知道 °C 应该如何和 Kelvin 互相转换。
普通字段
temperature: 200 °C
本体对齐后
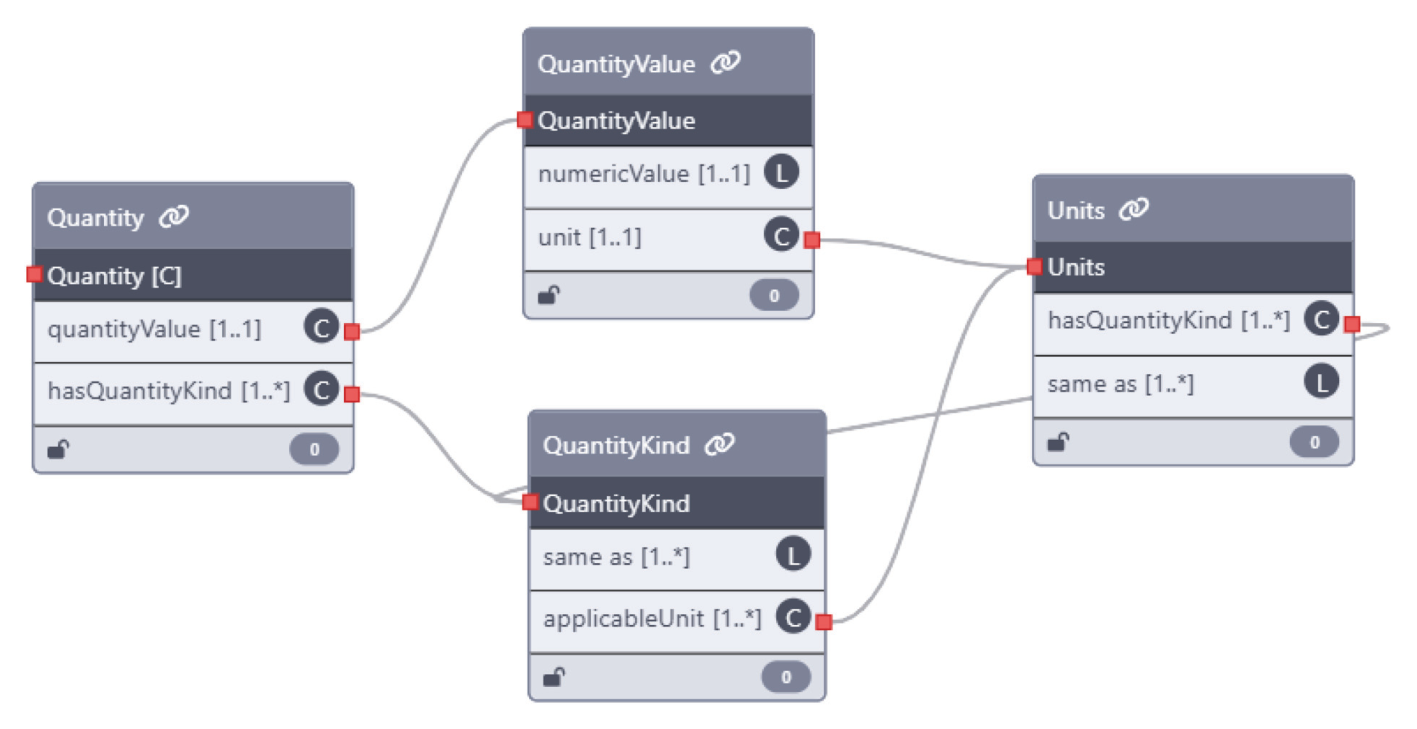
temperature: value: 200 unit: qudt:DEG_C quantityKind: qudt:Temperature
它解决了什么问题?
科学论文对人友好,但对机器不友好。尤其是实验流程,常常写得很自然,却很难直接变成数据库或知识图谱。
问题 1:字段不统一
一篇论文写 temperature,另一篇写 substrate temperature,还有一篇写 temp。人知道差不多,机器不一定知道。
问题 2:单位不统一
温度可能是 °C 或 K,时间可能是 s 或 ms。没有标准化,跨论文比较就很麻烦。
问题 3:LLM 会跑偏
LLM 能生成 JSON,但可能漏字段、乱分组、过度细化,或者生成看似合理但专家不认可的结构。
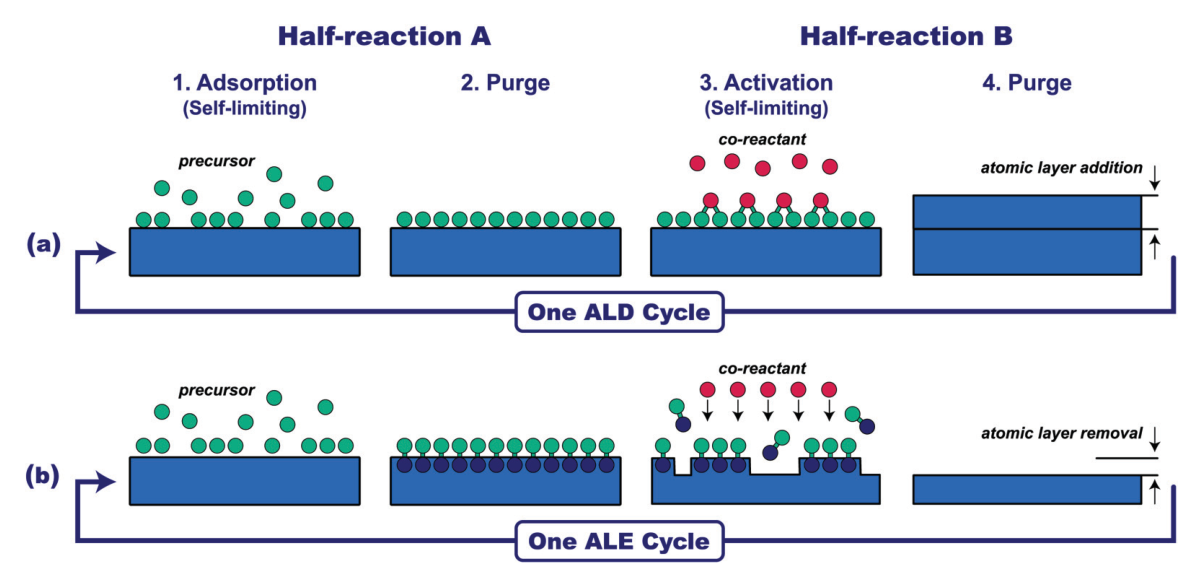
它用了什么方法?
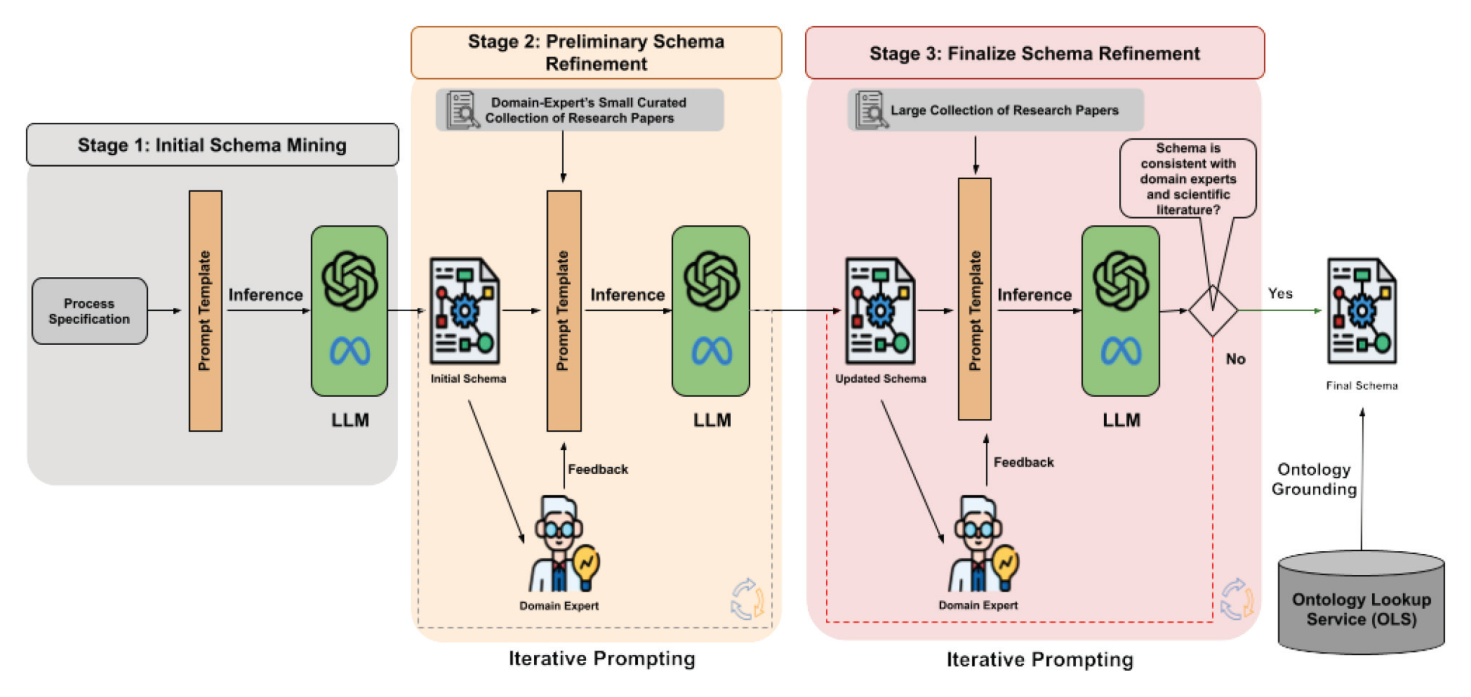
方法可以理解成四步:先让 LLM 生成草稿,再用论文和专家反馈不断修正,最后让 agent 把字段连到标准本体。
给一份工艺说明
专家先写一个 process specification,告诉模型这个工艺大概是什么。
让 LLM 出 schema 草稿
模型生成初始 JSON schema:有哪些字段、字段是什么意思、类型和单位是什么。
用论文和专家修正
先用少量高质量论文精修,再用更多论文泛化;专家可以写意见,也可以直接改 schema。
Agent 做本体对齐
把 temperature、pressure、energy、time 等字段连到 QUDT 的标准概念和单位。
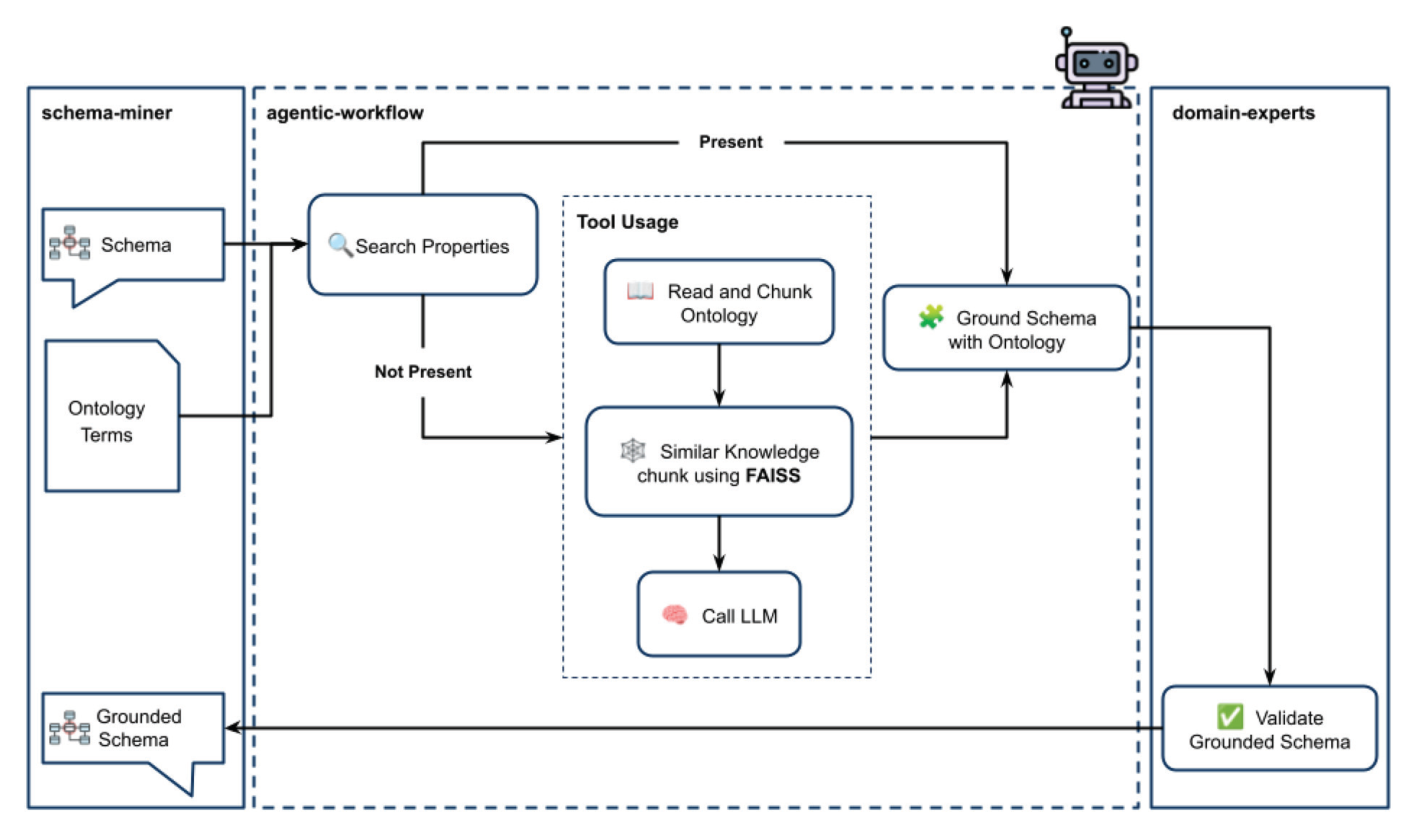
Agent 到底在干什么?
可以把 agent 想象成一个“本体对齐助理”。它不是重新读整篇论文,而是逐个检查 schema 字段,看这个字段能不能对齐到标准概念。
简单字段:直接匹配
比如 temperature、pressure、flow rate。agent 能直接在 QUDT 里找到对应的 QuantityKind 和 Unit。
temperature → QUDT Temperature °C → QUDT DEG_C
复杂字段:语义搜索
比如 growth per cycle。QUDT 里未必有同名概念,agent 会用 FAISS 找相关本体片段,再让 LLM 判断最接近的语义。
growth_per_cycle → related to Length / domain metric → ask expert to confirm
公式其实可以这样理解
不用被符号吓到。下面这些公式只是把刚才讲的流程写得更正式。
Schema 怎么一步步变好
每一轮 schema 都由上一轮 schema、当前论文资料、专家反馈共同决定:
简单说:模型不是一次生成完,而是不断吸收资料和专家意见。
字段怎么对齐本体
一个字段先尝试直接匹配;不行就检索本体,再交给 LLM 判断:
简单说:容易的直接查,难的用语义搜索和 LLM。
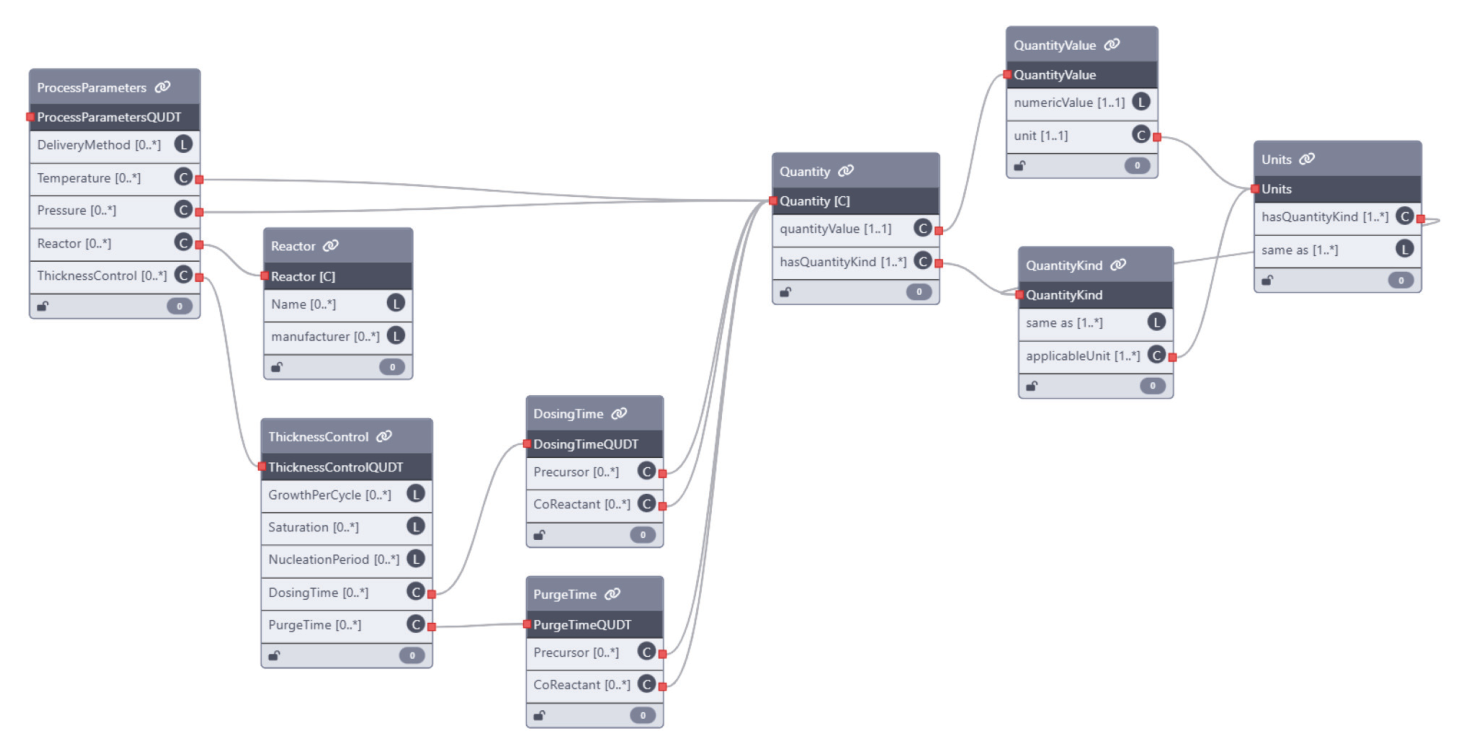
实验怎么做?
作者用 ALD 和 ALE 两种工艺测试系统,比较不同模型、不同专家反馈方式,以及 QUDT grounding 的效果。
模型
- GPT-4o
- GPT-4-turbo
- LLaMA 3.1 8B
反馈设置
- 只给自然语言反馈
- 只给专家修改后的 schema
- 两种反馈都给
- 不给专家反馈,作为 baseline
数据
- Stage 1:专家写的工艺说明
- Stage 2:约 1-10 篇精选论文
- Stage 3:最高约 100 篇更大规模论文
评价
- ROUGE-L、BLEU、BERTScore 比较 schema 文本相似度
- 专家评估 schema 是否合理
- 专家检查 QUDT grounding 是否正确
关键结果表:简化版
| 问题 | 结论 | 解释 |
|---|---|---|
| 哪种反馈最好? | 自然语言反馈 + 直接 schema 编辑 | 文字提供语义解释,schema 编辑提供结构约束。 |
| ALD 上谁更稳? | GPT-4o 和 LLaMA 3.1 8B | 它们更能保持结构,不容易乱加字段。 |
| ALE 上谁更稳? | GPT-4o 和 GPT-4-turbo | LLaMA 在大语料阶段更容易生成过度特化字段。 |
| Agent grounding 准吗? | 概念识别整体有效,但单位常需专家修 | 约 30% 的单位建议被专家调整,说明领域实践很重要。 |
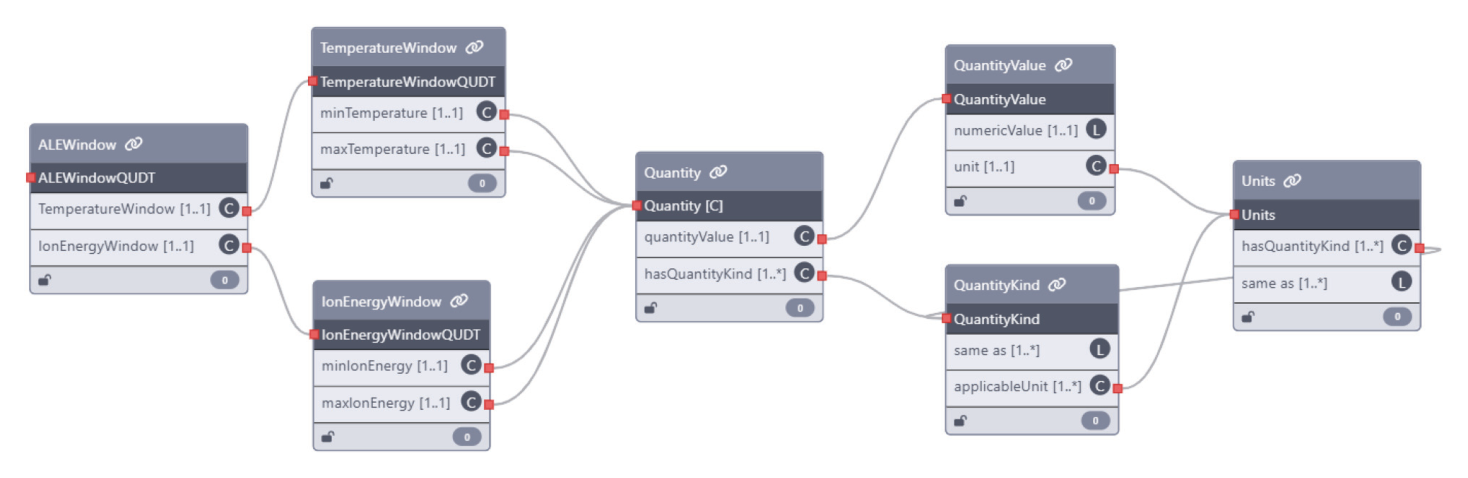
最后记住这几句话就够了
它解决的不是阅读问题
人本来就能读论文。它解决的是机器如何把论文变成可查、可比、可推理的数据。
LLM 不是终点
LLM 负责生成 schema 草稿,但专家反馈和 ontology grounding 才让结果可靠。
本体对齐是关键
只有字段连到 QUDT 这样的标准概念,跨论文、跨数据集比较才真正可行。
我的锐评
这篇工作的方向是对的,而且很务实。它知道科学 schema 不是靠 LLM 一句话就能生成的,需要专家、文献、本体和工具链一起工作。
优点
- 问题非常真实,贴近 AI4Science 和知识图谱落地。
- human-in-the-loop 设计合理,没有假装全自动万能。
- Agent + FAISS + QUDT 的 grounding 方案工程上很实用。
- ALD/ALE 案例选得好,能体现单位、工艺参数和过程结构的重要性。
不足
- 评价指标偏弱,ROUGE/BLEU/BERTScore 不太适合衡量 schema 是否科学正确。
- 缺少真正的 gold standard schema。
- Agent grounding 没有给出足够细的准确率、召回率、单位准确率。
- 跨领域泛化还主要是展望,没有实证。
One More Thing
论文最后还做了一个 Hugging Face Spaces 聊天应用。我的理解是,它真正指向的是一个“科学 schema IDE”:专家在界面里看字段 diff、看单位候选、看本体 URI、看来源证据,然后一键接受、拒绝或修改。